我的自建Git被ClaudeBot爬了!
2026年1月24日,凌晨3:35,收到来自阿里云的额度预警短信和邮件,告知本月云数据传输CDT中国内地免费公网流量仅剩20%,于是在我睡醒起床后,点开控制台...
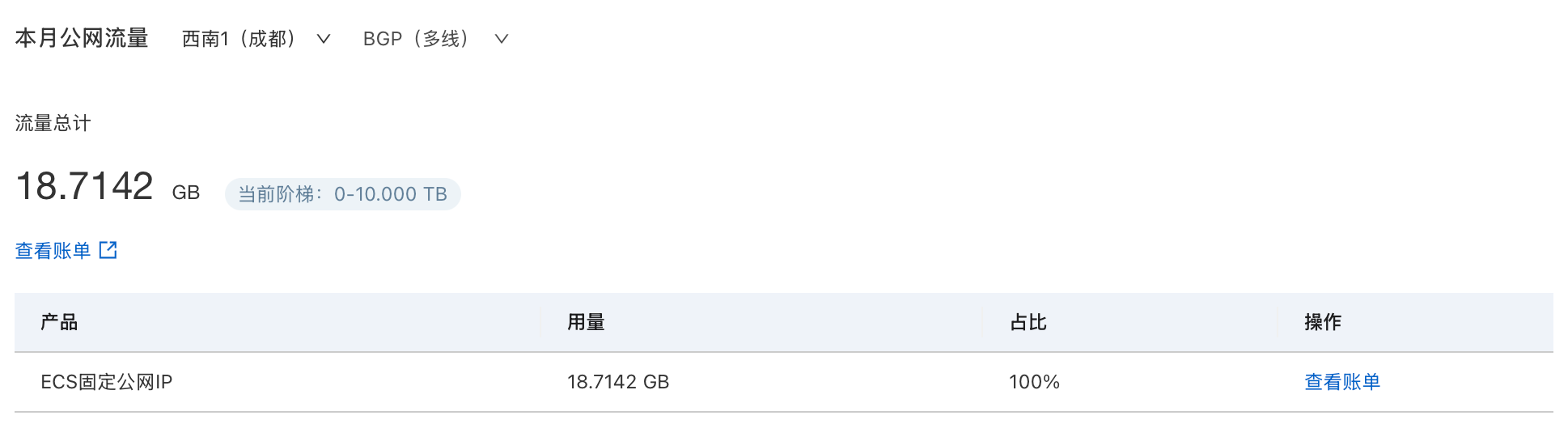
一看,好家伙!以前从来没收到过预警的,这个月直接快干超了!于是立即打开1Panel面板,查看近日监控指标,本次异常在CPU和网络监控上初见端倪
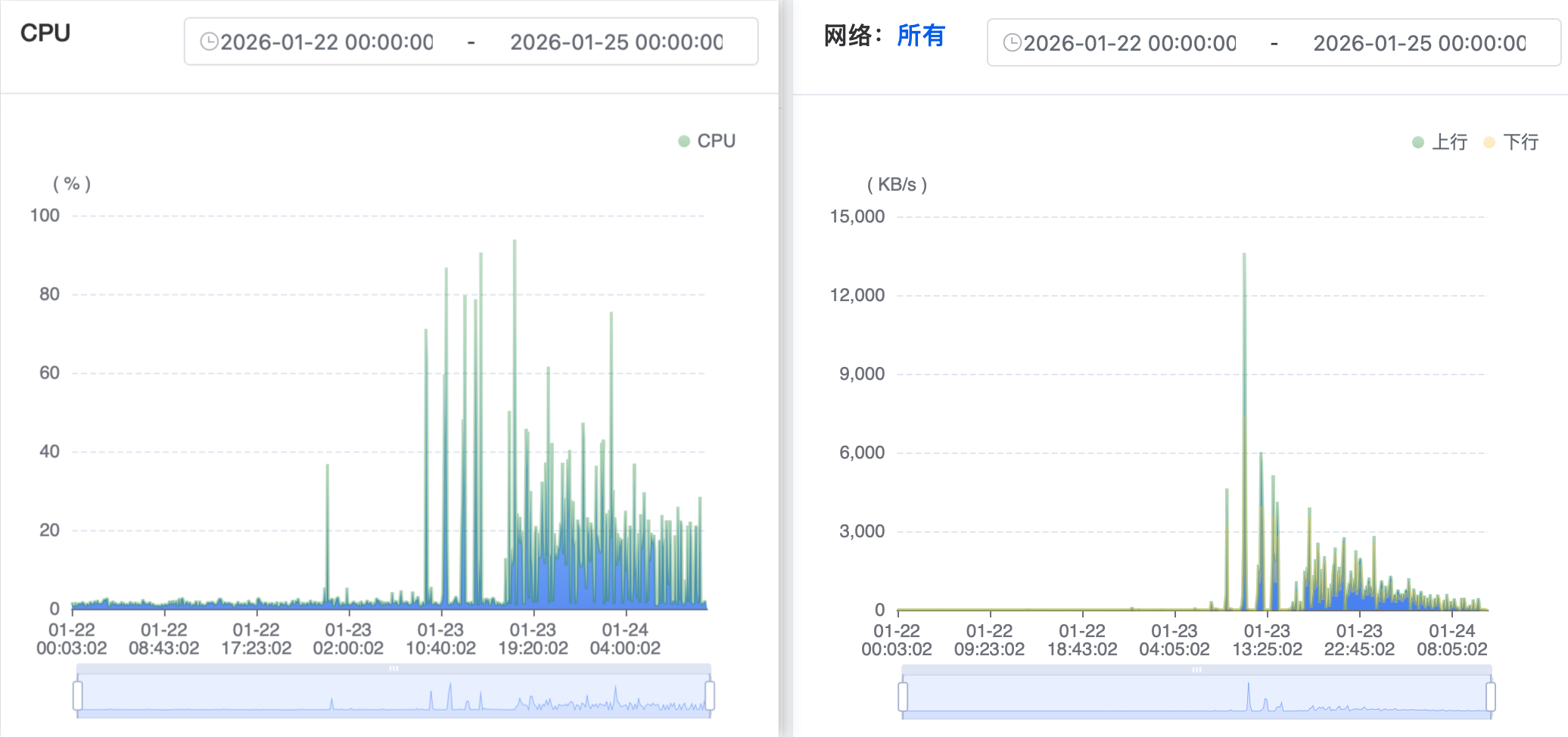
经历过前段时间的网络攻击后,我将服务器的端口限制的很严格,几乎只开了常用的端口,结合流量特证(周期性地收到请求、请求带宽不高,排除ddos),能让服务器出现这种情况的,目前我能想到的只有openResty和frp。
啥问题?
接下来开始排查。因为我的网站平时很少有人访问,能做到如此持久且“大量”的,我的第一反应是frp,于是打开frp-panel,发现所有隧道目前都是暂停状态,所以排除。接下来是openResty,打开1Panel的日志审计,打开网站日志-运行日志页面,挨个查看各个网站的访问情况。其中在git.tonesc.cn这个网站上发现一些异常:几乎每一分钟都有非常多的访问记录!这明显是不合理的!细看日志,发现:
216.73.216.85 - - [24/Jan/2026:10:54:15 +0800] "GET /tone/tonePage/src/commit/05c8fd067b3980b3a7f61b9517d21d8eadafe95f/apps/frontend/components/ui/pagination.tsx?display=rendered HTTP/2.0" 404 150 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" "-"
216.73.216.85 - - [24/Jan/2026:10:54:15 +0800] "GET /tone/tonePage/src/commit/a4fd4bf5ddb5a3e5387ee1f732125c311c397fa6/tone-page-web/lib/api/resource/list.ts?display=rendered HTTP/2.0" 404 150 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" "-"
216.73.216.85 - - [24/Jan/2026:10:54:15 +0800] "GET /tone/tonePage/rss/commit/b5aae0d5b4f3441acf53de2b965ef209f2e0a25a/tone-page-web/components/ui/collapsible.tsx HTTP/2.0" 404 150 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" "-"
216.73.216.85 - - [24/Jan/2026:10:54:15 +0800] "GET /tone/tonePage/src/commit/3e628013b6a51f384cac2d71b38aa9c51229c61d/tone-page-web/lib/api/user/index.ts?display=rendered HTTP/2.0" 404 150 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" "-"
216.73.216.85 - - [24/Jan/2026:10:54:15 +0800] "GET /tone/tonePage/src/commit/e940433b524d534f3be6132f5c427114a20b2fa1/tone-page-web/lib/api/user/me.ts?display=source HTTP/2.0" 404 150 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" "-"
几乎全是216.73.216.85这个ip访问的,并且请求头User-Agent出现重要字段:ClaudeBot!
联想到以前刷到过的文章,AI厂商为了训练自家AI,会疯狂爬取他人的源代码仓库,看样子,我的自建git也是被盯上了。由于该服务的用户并不多,且使用频率也不高,接下来第一件事,就是先暂停该网站的访问。其次,是应该禁止该爬虫的访问,或者说,是禁止所有这一类型的爬虫的访问。
咋解决?
禁止爬虫访问,第一步想到的是robots.txt这个君子协议。我的自建Git服务用的是Gitea,因此查询文档得到:
使用自定义 /robots.txt
将 想要展示的内容 存放在 custom 目录中的 robots.txt 文件来让 Gitea 使用自定义的/robots.txt (默认:空 404)。
我的Gitea服务是用systemd托管的,通过查询
tone@iZ2vc1lqezrwtfjmoi3x9zZ:~$ sudo systemctl status gitea
● gitea.service - Gitea (Git with a cup of tea)
Loaded: loaded (/etc/systemd/system/gitea.service; enabled; preset: enabled)
Active: active (running) since Sat 2025-12-06 10:57:50 CST; 1 month 18 days ago
Main PID: 22313 (gitea)
Tasks: 46 (limit: 1966)
Memory: 398.6M
CPU: 15h 40min 35.177s
CGroup: /system.slice/gitea.service
└─22313 /usr/local/bin/gitea web --config /var/lib/gitea/custom/app.ini
得到custom目录所在位置,因此在这里新建robots.txt文件,写入如下部分,最后修改文件归属用户和用户组为git:git,这部分就搞定了。
User-agent: *
Disallow: /
接下来是禁止现有的爬虫爬取内容,需要在网站的配置文件中添加以下内容,根据UserAgent判定访问者身份,不合规的直接返回444:
set $is_human 0;
if ($http_user_agent ~* "Mozilla/5\.0" ) {
set $is_human 1;
}
if ($http_user_agent ~* "(Chrome|Chromium|Firefox|Safari|Edg|Edge|OPR)" ) {
set $is_human 1;
}
if ($http_user_agent ~* "(ClaudeBot|anthropic|GPTBot|OpenAI|Perplexity|Amazonbot|Bytespider|CCBot|AI2Bot|Baiduspider|bingbot|Googlebot|Yandex)" ) {
set $is_human 0;
}
if ($is_human = 0) {
return 444;
}
最后,根据配置文件中提到的/www/sites/git.tonesc.cn/proxy/*.conf前往/opt/1panel/www/sites/git.tonesc.cn/proxy/root.conf文件,加上一段
add_header X-Robots-Tag "noindex, nofollow, noarchive, nosnippet, noimageindex, notranslate";
重启一下openResty,让配置生效,搞定~
解决了吗?
最最后,检测配置是否生效
tone@MacTONE ~ % curl -I https://git.tonesc.cn/
curl: (92) HTTP/2 stream 1 was not closed cleanly: PROTOCOL_ERROR (err 1)
tone@MacTONE ~ % curl -I --http2 -A "Mozilla/5.0" https://git.tonesc.cn/
HTTP/2 200
server: openresty
date: Sat, 24 Jan 2026 05:58:49 GMT
cache-control: no-cache
strict-transport-security: max-age=31536000
x-robots-tag: noindex, nofollow, noarchive, nosnippet, noimageindex, notranslate
tone@MacTONE ~ % curl --http2 -A "Mozilla/5.0" https://git.tonesc.cn/robots.txt
User-agent: *
Disallow: /
- 不带任何请求头,从协议层面就直接被掐断了
- 正常模拟用户浏览器访问,有我们设置的x-robots-tag响应头
- 访问robots.txt,能够得到正确的内容
经过上述配置,目前大多数爬虫应该都不会再访问该网站了。已经用三道关卡去禁止爬虫获取网站内容了,再爬就不礼貌了。
最最最后,再瞅一眼日志:
216.73.216.85 - - [24/Jan/2026:11:55:13 +0800] "GET /robots.txt HTTP/2.0" 444 0 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" "-"
216.73.216.85 - - [24/Jan/2026:12:55:16 +0800] "GET /robots.txt HTTP/2.0" 444 0 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" "-"
爬虫发现服务器连/robots.txt都不想给它看🤣后续也就没有再访问了,还是很听话的爬虫一只~(虽然原则上robots.txt是应该可以让它看的,但是...又不是不能用,对吧)
等待一段时间后,发现网络上下行几乎归零,后续也没有再反弹
至此,该问题暂时就解决了~
2026年1月24日 23:39,上述方案出问题了
当我编写完代码,准备推送到git仓库时,发现我自己的客户端被我的服务器当爬虫处理了....
所以调整openResty部分的拦截代码:
set $is_human 1;
if ($http_user_agent ~* "(ClaudeBot|anthropic|GPTBot|OpenAI|Perplexity|Amazonbot|Bytespider|CCBot|AI2Bot|Baiduspider|bingbot|Googlebot|Yandex)" ) {
set $is_human 0;
}
至此,问题应该暂时又被解决了...